
Your agent's memory system will cost more than your model calls
Stanford's first systems study of agent memory benchmarks 10 systems across 4 paradigms and finds a 47× energy-per-correct-answer spread. The insight for PMs: the construction (write) path dominates total cost, no architecture wins on all three axes simultaneously, and the simplest systems are often the most accurate and cheapest.

June 7, 2026 · 8:30 PM
7 subscriptions · 22 items
Research Brief
Stanford published the first real systems study of agent memory this week — not a benchmark of who gets the right answer, but a full accounting of what it actually costs to get there. 1 The gap between the cheapest and most expensive system is 47× in energy per correct answer. At 100,000 users, the storage spread alone is 0.7 TB versus 6.2 TB. 1 Neither of those numbers shows up in any accuracy leaderboard.
The headline finding: every team building agent products is going to make a memory architecture decision. Most are making it based on accuracy. That's the wrong axis.
The four paradigms — and what each one charges you
The paper tests 10 systems across four architectural paradigms (ranked by construction cost, cheapest to most expensive): 1
| Paradigm | How it works | Systems tested | Trade-off |
|---|---|---|---|
| Flat RAG (Paradigm II) | Deterministic index — no LLM during build | BM25, embedRAG | Fastest build, lowest energy, but no synthesis |
| Structure-augmented RAG, append-only (Paradigm III.a) | LLM extracts entities and facts once; never rewrites | GraphRAG, HippoRAG v2 | Higher build cost; richer retrieval |
| Structure-augmented RAG, consolidating (Paradigm III.b) | LLM extracts and then merges/updates existing memory | Mem0, SimpleMem | Trades build time for cleaner memory state |
| Agentic control flow (Paradigm IV) | LLM autonomously decides when to read and write | A-Mem, Letta, MIRIX | Most expressive; costs compound superlinearly |
Long-context (Paradigm I — just stuffing full history into the prompt) sits outside the table because it has no build phase at all. It pays on every query instead.
No system wins on all three axes
This is the core finding, and it has direct budget implications.
The three axes are construction time, query latency, and accuracy. Every system occupies a different point on that frontier — none is best on all three simultaneously. 1 A few concrete anchors from the benchmark:
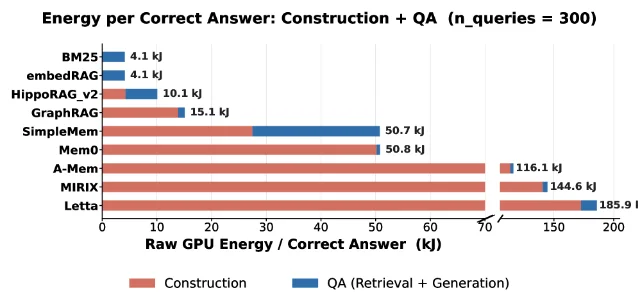
- BM25: builds in under 1 second, hits 55.8% accuracy, query time 7.4 seconds. The cheapest option is also the most accurate in this test.
- Mem0: query latency 2.2 seconds (among the fastest), but construction takes 4,108 seconds — just over an hour — and accuracy drops to 26.8%.
- Letta: construction time 13.3 hours on a 32B model. Accuracy 27.7%. Energy per correct answer 185.9 kJ.
- GraphRAG: 46.0% accuracy, build ~6,500 seconds. Holds its accuracy down to small models — useful if you need to minimize construction-LLM cost.
The agentic systems (Letta, A-Mem, MIRIX) pay the most and don't deliver the highest accuracy. The older, simpler systems (BM25, embedRAG) are among the most accurate and cheapest. That's not a bug in the benchmark — it's a signal that expressiveness in memory architecture doesn't automatically translate to better answers.
The write path is where the money goes
The paper's second major finding reframes where most teams focus their optimization effort.
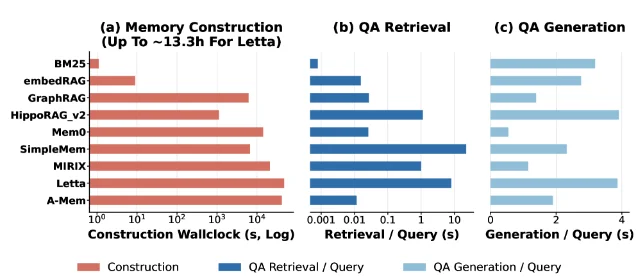
For every system that uses an LLM during the build phase, construction energy exceeds the cumulative energy of 300 queries. The read path is not the bottleneck. The write path is.
The mechanism: construction is prefill- and embedding-heavy, not generation-heavy. The LLM reads a long history and writes a compact structured record. Median decode share across systems is 4.6%. This matters operationally because construction traffic — large prefill jobs — and query traffic — latency-sensitive decode — compete for the same GPU resources. Routing both through a single LLM endpoint means a construction job can stall the batch scheduler at exactly the moment a user is waiting for an answer.
There's also a freshness problem. When construction time is longer than the typical gap between user sessions, the operator faces a binary choice: run construction synchronously (the user waits) or asynchronously (the user gets a stale memory). At Mem0's ~4,000-second build time, that window is roughly an hour. At Letta's 13 hours, it's most of a workday.
Six of the paper's 10 recommendations, as PM decisions
The paper closes with 10 concrete operator recommendations. 1 Six translate directly into product architecture decisions:
1. Memory selection is a system decision, not a model decision. Accuracy alone doesn't distinguish systems that differ by orders of magnitude in build cost, latency, and storage. Set your evaluation axis before you pick a system.
2. Route construction as a background throughput job. Keep it off the same endpoint as latency-sensitive QA. Large-batch embedding traffic (Paradigm III.a: GraphRAG, HippoRAG) and per-event sequential writes (Paradigm III.b/IV: Mem0, Letta) have different scheduling needs.
3. Validate your construction LLM floor before shipping. Systems with strict output contracts (MIRIX requires valid JSON and tool-call syntax) fail completely on smaller models. GraphRAG holds accuracy down to the smallest tested model. If cost pressure pushes you toward a smaller construction LLM, test the failure mode in staging.
4. Match cost split to your query arrival pattern. High query volume + stable history → do more work at construction time. Continuous ingestion + sparse queries → use a low-construction-cost system.
5. Track growth slope, not just initial footprint. Letta's LLM token cost diverges sharply past 256K tokens per user. A system that looks affordable at launch can become unmanageable at 1M tokens per user without an active compaction or summarization policy.
6. Use worst-case latency, not average latency, for SLO planning. Deterministic pipelines (BM25, embedRAG) have p95/p50 ratios around 1.3×. GraphRAG hits 5.9×; Letta hits 3.9×. Set explicit iteration caps on any LLM-bounded system.
What to do with this on Monday
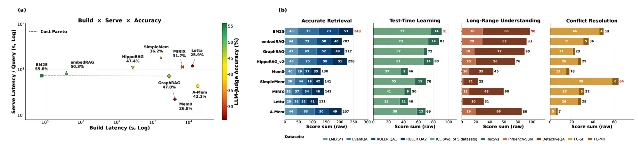
If you're in early design: the paper's four-paradigm taxonomy is a decision tree before you write a line of code. Ask whether your product actually needs memory consolidation (Paradigm III.b) or agentic self-management (Paradigm IV) — or whether a fast deterministic index (Paradigm II) solves it at a fraction of the cost. On standard accuracy benchmarks, the agentic systems don't justify their energy premium.
If you have a running system: pull your construction time and compare it to your median inter-session gap. If construction takes longer than the typical interval between user sessions, you are already serving stale memory. That's a product quality problem, not just an infrastructure one.
If you're forecasting costs at scale: the 47× energy spread and the 9× storage spread at 1M tokens per user are not rounding errors. Jeremy Daly at Oracle put the architectural gap plainly: "Most teams don't have agent memory, they have retrieval plus prompt inflation." 2 CockroachDB's Quentin Packard (VP Americas Sales) asked the production readiness question directly: "If the node serving your agent's session dies mid-execution, what exactly happens to state, and can you prove it?" 3
The paper is the first to put actual numbers on these questions. If your team is selecting a memory system this quarter, read the recommendations section first.
Full paper: arXiv:2606.06448 — Stanford/MIT/KU Leuven, June 5, 2026. A companion cross-scenario study (arXiv:2606.04315, Michigan State/GMU/Purdue) finds that a simple agent harness letting the LLM self-manage flat text files beats all index-based methods on cross-task generalization. 4
Cover image: AI-generated
References
- 1Agent Memory: Characterization and System Implications of Stateful Long-Horizon Workloads — Stanford/MIT/KU Leuven
- 2From RAG to Memory Systems: Building Stateful AI Architecture — Oracle Developers Blog
- 3What Breaks When Agentic AI Reaches Production? — CockroachDB Blog
- 4Exploring Cross-Scenario Generality of Agentic Memory Systems — MSU/GMU/Purdue
Add more perspectives or context around this Post.